Review: Oggz, Laserpod, Mathmos Color Bubble #
I've been looking for interesting lights to use at night. I wanted something colorful, not too distracting, and ideally, portable. I bought 3 Oggz, a Laserpod, and a Mathmos Color Bubble.
Oggz

Oggz are soft egg-shaped lights that you can hold in your hand. They slowly change colors, from blue to green to red and back (this is not configurable). There's a switch on the bottom to turn them on and off. You can place them on the base to have them run continually, or you can just pick them up and take them with you (the battery lasts 6–8 hours). When you put them back on the base they'll recharge. There are a few downsides of the Oggz:
- You can't adjust the color changing. It would've been nice to have a way to pause it, so that you could keep it at a certain color.
- The switch at the bottom is not easy to turn on in the dark. I used the Oggz as nightlights for a while, and until you turn them on you can't see the switch, which you need for turning them on.
- The red light is much darker than the green and blue. This means the overall brightness changes, not just the color. This is especially unwelcome when you're using it as a nightlight, because your eyes adjust to the blue and green brightness, and then you get plunged into darkness when it cycles to red.
Despite these minor problems, I do like the Oggz.
Laserpod

The Laserpod contains a red laser and blue LEDs, plus a diffraction crystal and a cover. The lights rotate slowly. You can use it in several modes:
- Uncovered, the Laserpod will project lights onto the ceiling. It's not bright enough to see except at night with all the lights off. Covered, the Laserpod will project lights onto a frosted dome (it comes with two, one tall and one short). When covered it's easier to see the patterns.
- Red light only, you will get the laser beam, which is either bright points or laser lines. You can also turn on blue LEDs to add to the ambience, but they don't project any sharp patterns. There is no mode to use the blue LEDs without the red laser.
- Unfiltered, the Laserpod will project its laser as points onto the ceiling or one of the covers. It's more interesting to use the diffraction crystal, which will turn the points into cool patterns. You can also use your own objects; I tried a small crystal I have and was able to split the laser points into lots of dots moving around on the ceiling.
Pictured is the Laserpod with only the red laser on, the diffraction crystal, and the tall cover. That's my favorite of the many ways of using it. Unfortunately the motor can be loud at times, so I can't leave this on at night when going to sleep, and it's dark enough that it's not really useful to leave this on during the day or in the evening with other lights on. So I find that I rarely ever have an occasion to use it. For the high price, the noise, and the lack of brightness, I cannot recommend the Laserpod.
Mathmos Color Bubble
I don't have a picture of this, but you can see one at ThinkGeek. I was hoping for something that addressed the flaws of the Oggz. The Mathmos bubble can be turned on or off with just a squeeze, according to the product literature. However, it's a bit tougher than that because the squeeze has to be on a particular side of the sphere. Given that spheres have no sides, it becomes hard to find the right place when it's dark. It's always blue, not changing colors or brightness, so it's a better nightlight than the Oggz. Unlike the Oggz, which can be recharged simply by putting them down, the Mathmos has to be plugged in with a special cable. The Mathmos has a nice soft feel like the Oggz, but it's significantly heavier. The Oggz are light enough and feel durable enough that I am comfortable throwing them across the room; the Mathmos is heavy enough that I won't play with it the same way.
Conclusion
I like the Oggz most of all. They're much cheaper than the Mathmos and there are three of them, not just one. The egg shape is a little nicer than a sphere. The Laserpod is the most expensive of all, and after the initial coolness wore off, it just hasn't been enjoyable. I recommend the Oggz.
Labels: review
China, the Dollar, and Christmas #
China recently stated that they had too many dollars, and were looking to diversify. China has over half a trillion dollars, and if they start selling them, the dollar will drop. The announcement alone caused the dollar to drop in value.
If the dollar drops in value, China will get less from selling them. It doesn't make sense for China to announce something that will make the dollar drop. They should instead quietly sell dollars.
So why did they announce it? My theory is that they want the dollar to drop but are not intending to sell dollars for a few months, during which the dollar will recover.
If the dollar drops in value, it will take more dollars to buy things from China. Normally, that would mean that fewer goods would be bought. However, it's Christmas shopping season right now, and parents are going to buy toys for their kids no matter what. Furthermore, they're shopping around. That means retail stores (and online stores) have to keep prices low—they can't raise them to reflect the lower value of the dollar (and thus increased cost of goods). With prices staying low and Christmas coming up in a few weeks, demand will remain high.
Since the amount of goods bought will stay the same, the cost paid by retailers has gone up, and the price paid by consumers has stayed the same, the big winner in all of this is China, and the losers are the retailers. A portion of their profits will go to currency exchange. If I were playing the stock market, I'd short the retailers that sell lots of goods from China.
If I were in charge of the Chinese currency, I'd make some announcement right after Thanksgiving about my wanting to get rid of dollars, but I wouldn't actually sell any dollars. That way I can get even more dollars from all the Christmas shoppers than I normally would have. A few months later I'd quietly sell dollars. I certainly wouldn't announce that I'm going to sell dollars right before I sell them. That'd be dumb.
Second Life: Svarga #
If you're in Second Life, you should check out Svarga [SLUrl]. It's an exotic jungle island with pathways, towers, musical instruments, isolation room, fountains, temple compound, secret underground chamber, lookout posts, a second island, and even its own ecosystem (birds, bees, flowers, plants, trees, weather). There are lots of details that are easily missed the first time through. When you get there, be sure to take the guided tour by sitting on the hovering tour chair.
Svarga is my favorite place in Second Life. Unfortunately it may not be around for much longer.
Labels: review
Daylight Savings Time #
DST 2013 begins Sunday, March 10.
Twice a year I get annoyed by Daylight Saving Time. In 2006, I got annoyed enough that I started to write a rant about why we should get rid of it, and then I started to find reasons we should keep it. By the time I was finished with my rant, I decided I prefer a different solution: let's keep it year round!

Here's my my rant: Daylight Saving Time.
Update: [2014-03-08] By 2012, I grew to accept DST. Sunrise times are kept within a narrower range, as you can see by looking at the blue line on this graph. Without DST, you either have the sun rising way too early in summer, or you have the sun rising way too late in the winter. :-(
Labels: future
New site redesign notes #
In my last post, I described the new implementation of my web pages and hinted that there was a new design as well. You can compare the old design to the new design to see:
- There's a lot less color. This is probably the biggest change. I like bold colors, but it was too much; it overwhelmed the page and made the headers (which also used the same color) harder to pick out. Section headers are now black (with just a small square of color); the page border is now subdued.
- The text is more tightly packed. (I changed the leading from 1.5 to 1.25.) I have mixed feelings about this; I may change it back.
- Text matches the line spacing of the main text as much as possible. I'm a little skeptical of this rule, as it seems to result from limitations in printing presses, but a friend of mine who really knows his typography recommends it.
- There's a print-friendly version of the style using
@media screenstyle rules to enclose sections designed for regular screens and@media printstyle rules to enclose sections designed for printing. The navigation bar, sans-serif body font, shadows, and colored backgrounds are removed for printing. I didn't write any rules for other media types. - There's more whitespace on the left, except to the left of headings.* This makes headings a little easier to pick out.
- The page contents have a soft shadow around them; preformatted text has a soft shadow inside.*
The items with a * are enabled by the implementation; they were not something I could easily do with CSS alone. Each section is now a container with both a title and contents:
<x:section title="Header">
<p>
Paragraph 1.
</p>
<p>
Paragraph 2.
</p>
</x:section>
In HTML, the sections are implicit—they are whatever occurs between headers. In the my XML content, the sections are explicit. That way I can apply a style to the section, such as adding a margin to the left. This is something I've long wanted through various redesigns. Sometimes I want a border; sometimes I want a horizontal line separating sections; sometimes I want them to be a different color. Now that I have each section marked, I can choose a combination of HTML tags and CSS rules to achieve the effect I want.
I treated the document in the same way as the sections. In HTML, the header and footer are inside the document body. This means any style rules that apply to the body contents (such as margins) also apply to the header and footer. I often want the header and footer to span the entire width of the document, so this makes the HTML messier. With XSLT, I can create a new document body (with <div>) and move the header and footer outside of it. To get the shadow effect, I use three divs, each with a different border color. Preformatted text gets surrounded by three divs as well. XSLT lets me inject new elements that are used purely for formatting.
I tried using serifs for the body font but it was too much of a change for me, and it doesn't work as well on lower dpi screens. There are still a few things to clean up, including the rendering in Internet Explorer, but overall I'm pretty happy with the style.
Labels: project
New site design and implementation #
As long as I've been writing web pages, I've experimented with ways to manage them. Long ago I used the C preprocessor to give me server-side includes and simple macros. It was a mess, since the C preprocessor parses single quotes and double slashes (for C character constants and C++ comments), and both of those occur in other contexts in web pages. Later on I built something that could automatically build navigation trees for each page. I also experimented with but never fully adopted a system that would let me write HTML in a simpler syntax. I built tools that would take multiple text files and assemble them into a larger page. I also tried using third party tools, like LaTeX2HTML. I eventually abandoned all of these systems. They were too complex and introduced dependencies between input files, and I then had to manage those dependencies.
The last time I had the web page management itch, I wrote down what I wanted out of any new system I set up:
- Portable. I want to depend on as few external tools as possible, so that I could run this on a variety of systems, including Windows, Linux, Mac, and the restricted environment where my web pages are hosted.
- Straightforward. I had abandoned several of my previous systems because they imposed restrictions on what I could put into my document. I'm comfortable with HTML, and I'd like to just write HTML as much as possible. The more abstractions I put in between my system and the final output, the more restrictive and complex it will be.
- Fast. Several of my previous systems had to analyze all of my documents in order to rebuild any of them. In particular, navigation trees require analyzing other nodes in order to create the links. If I only edit one document, I want my system to regenerate only one HTML file. Therefore this rule requires that I do not put in navigation trees.
- Simple. I'm lazy. I don't want to write a complicated system to manage my pages. I just want to get the low hanging fruit and not worry about solving all the problems.
- Static. I have to produce static HTML; I don't have a web host where I can run web apps or CGI scripts.
I ended up learning and using XSLT. I do not particularly like XSLT, but it's a reasonable tool to start with. When HTML and XML documents are viewed as trees, XSLT is used to transform (rearrange, erase, and add) tree nodes.
The first step was to extract the content out of my existing web pages. Each page has a mix of template and content. The extrator separated them. I had written these pages in different styles over a period of ten years, so the headers, navigation, HTML style, etc. are not consistent. Some of the pages were generated by other tools I had used. While looking at the old HTML, I decided that I would not be able to treat them uniformly. I added to my requirements:
- Optional. Some pages will use the new system and some pages will not. I will not migrate everything at once.
I wrote XSLT to extract content out of some of my web pages. I grouped the pages by their implementation and style. I handled the extraction in four ways:
- If the page already fit my extractor, I left it alone.
- If the page with some minor changes would fit my extractor, I made those changes to the page.
- If the page would fit the extractor with minor changes, I made those changes to the extractor.
- If the page would require major changes to either it or the extractor, I excluded it.
I thus had a set of pages (some modified), a set of pages to exclude, and an extractor. The extracted content was in the form of XML files (which were mostly HTML, with some XML meta information.) I tested them by inspection; it was hard to tell whether I got things right until the second step: injection. In the second step, I combined the content of each page and a new template I had written, producing HTML. I then compared the new pages with the old pages, side by side, in several browsers, until I was reasonably happy with the results. I rapidly iterated, each time fixing the extactor, the injector, or the old HTML (so that it'd extract better). Any pages I couldn't fix at this step I wrote down for later fixing.
To summarize, during this stage of development I had old pages, an extractor, a set of content pages (the results of the extractor), an injector, and new pages (the results of the injector). Some pages I had excluded from the entire process, and others I had marked as needing repair. I also had a set of things I'd like to do that XSLT couldn't handle.
After testing the output extensively, I was finally ready to make the switch. Tonight I replaced the old pages with the new ones. I no longer run the extractor. This means the content pages are no longer being overwritten, so I can now edit those pages instead of the old web pages. I went through the list of pages that needed repairs and fixed them. I tested every page on the new site, fixed up a few minor leftover problems, and pushed the pages to the live site.
I'm much happier with the new system. It's not a series of hacks and it's not custom code. It's using XML and a very simple shell script. It runs on Windows, Mac, and Linux. There is still more to do though. Not all of my pages use the new system or my new style sheet. Some parts of my site, including the blog, will continue to use an external content management system, so I will apply my new stylesheet and template without using the XML injector. There are a few more minor features that I want to implement, and there are more pages to clean up. I'm not in a rush to do any of this; it'll probably take a month or two. I've also been reluctant to edit my pages until now, because any changes I made had to be duplicated on the development pages (which I had modified to make the extractor work). Now that the new pages are up, I can resume working on the content of my pages.
I do recommend that people look into XSLT, but I think it's not sufficient for most needs. It does handle a large set of simple cases though; I'll fill in the gaps with some Python or Ruby scripts. If you find things on my site that don't work properly, let me know; I'm sure there are bugs remaining.
Labels: project
Advice for naming products #
In the age of the search engine, my naming advice: make sure people can search for your product. That means don't use a common word (you have to compete with all the pages already using it): Word, Excel, Windows, Apple, Office, Backpack, Ask, Live. Don't use a misspelled common word (users, upon hearing the name, will not know how to spell your variant): Novell, Digg, Topix, Froogle. Don't use capitalization or punctuation to stand out (search engines and search engine users often ignore capitalization and punctuation): C#, .NET, del.icio.us. Don't use names that aren't even in Unicode (the artist formerly known as "the artist formerly known as Prince"). It's okay but not great to use a common word that isn't commonly used on the web: Amazon, Dell, Ta-Da, Macintosh, Mac, Safari, Basecamp. It is fine to use misspellings of uncommon words, but you need to make sure people learn to use your spelling: Google, Flickr. It's better to use two easily spelled words mashed together: PlayStation, MicroSoft, WordPerfect, SketchUp, HotMail, FireFox; or to attach a short distinguishing mark to a common word: eBay, 43Things, GMail, 3Com, iPod, XBox, 30Boxes, 37Signals. If you're going to come up with a brand new word, make sure it's easy to spell once you hear it: Netscape, Akamai, Comcast, Honda, Lego. Don't use a name that's a subset of another name unless the product is a variant of the shorter name: Mac Pro, MacBook, MacBook Pro.
Don't pick a name like Zune unless you have enough marketing muscle to teach everyone that it's Zune, not Zoon. Try searching for zoon and see what you get. As of this post, the first page of search results doesn't mention Microsoft Zune at all. Every search for zoon is a lost chance to get a customer.
Many of the above names succeeded despite being bad because they got started before the web became big. But if you're starting a brand new product and call it "Word", I think you'll be shooting yourself in the foot. If you make it hard for people to find you, you'll have fewer customers and you'll make it hard to get the network effects that would bring in even more customers.
It would be interesting to see if there's a correlation between names and popularity, but it would probably be impossible to study this without examining parallel universes.
Labels: future
Bogus bank privacy statements #
I saw this in a bank privacy statement:
INFORMATION WE DISCLOSE
We do not disclose Customer Information about our present or former customers to third parties except as permitted by law.
So all they're really saying here is that they're not breaking the law. But that's all. They're willing to give out private information as much as possible (without breaking the law). Ugh!
Privacy Laws #
Here's an idea: privacy-invading laws (RFID passports, GPS tolls, speed monitoring) should apply to lawmakers for one year before they apply to the general public. I think lawmakers would have to think about the laws more carefully if they were the ones being watched. We can consider it “beta testing”.
Paint.NET is nice #
I usually use The Gimp for image manipulation. It's like Photoshop in that it's a complex interface designed for complex tasks. Most of my needs are simple though. They're more complex than what Microsoft Paint can handle but nowhere near what Gimp can handle. I recently tried Paint.NET after reading some good reviews, and I'm really happy with it. It's very easy to use and has a nice interface. All I've done so far is cropping, working with layers, painting in various colors, and adding text. Next time I need to manipulate an image, I'll likely to use Paint.NET instead of Gimp.
Labels: project
Stupid commercial: HP #
Hewlett Packard is running a commercial for their color printers and scanners. In the commercial, a child is at school, giving a report about planets. His speech is of the form, “I scanned this planet in from a magazine,” … “I printed this out on an HP XXXX color printer,” etc. He never says anything about the planets. All he did is scan some pages from a magazine and print them out. Throughout his speech he gets applause.
Is this what school reports are supposed to be? There’s no content! Maybe HP is trying to appeal to people who don’t think. Argh!
Mac OS X window management: Spooky #
To make the use of my computer screen space, I move windows to the edge of the screen. That way there's no wasted space between the edge of the window and the edge of the screen. In Windows, I use The Wonderful Icon for this. In Linux, I used the Sawfish window manager (but I see no way to do this in Metacity, the preferred GNOME window manager). In Mac OS X, I've been manually moving windows around. Today I found Spooky, a set of scripts that let you move and resize windows to the screen edge.
Spooky isn't user friendly. It's a set of scripts that you have to modify. Here's what I did:
- Put Spooky into a folder.
- Turn on “access” for universal devices (see the Spooky readme).
- Edit the Spooky starter script to fix what appears to be a script error. I changed
do shell script ("defaults write net.doernte.spooky \"pathToSpooky\" " & spookyFile)to
do shell script ("defaults write net.doernte.spooky pathToSpooky \"" & spookyFile & "\"") - Copy the Spooky starter script to one script for each action (see the Spooky readme):
for action in maximize centerWindow growWindow shrinkWindow maxBottomLeft maxBottomRight maxBottom maxLeft maxRight maxTopLeft maxTopRight maxTop moveBottomLeft moveBottomRight moveBottom moveLeft moveRight moveTopLeft moveTopRight moveTop zoomWindow; do cp spooky\ starter.scpt spooky.$action.scpt; done - I then had to edit each of these scripts in Script Editor, uncommenting out the line corresponding to the action for that script. In
spooky.moveTop.scptfor example I uncommented outspooky("moveTop"). I would've liked to automate this using perl, but Applescripts are stored in some binary format (why?!). - Finally, I assigned hotkeys to run the scripts using Quicksilver's custom triggers. This was quite a pain, as Quicksilver didn't pick up these applications, so I had to drag each action manually into a custom trigger. I gave them the keybindings suggested in the Spooky readme.
Although setting things up was more of a pain than I'm used to, now that they're set up, I'm much happier. For my browser, which I want on the right side of the screen, I use Ctrl-Right, Ctrl-Shift-Down, Ctrl-Shift-Up to position and size it. For my work window (usually Emacs), the sequence is similar except I start with Ctrl-Left. I'm much happier having windows go to the edge of the screen; now I don't have to precisely position and size them with the mouse.
Update: [2014-07-03] I haven't used Spooky for quite a while. I now use BetterTouchTool and Alfred. But if you're looking for something programmable like Spooky, look at Hydra.
Update: [2016] Also take a look at BetterSnapTool, Sticker, Slate (for power users), Divvy, Moom, Spectacle. There are many more. I use Stay and Alfred these days.
Mac Appearance: Limit Choice #
The Mac seems to limit your choices when it comes to its appearance. Maybe that's what makes it “easy” to use. For example, I use a solid desktop background. What does Windows offer me? A color selection dialog that lets me choose one of 16,777,216 colors. What does Linux (GNOME) offer me? A color selection dialog that lets me choose any color, or a gradient between two colors (281,474,976,710,656 possibilities). What does Mac offer me? A choice of 10 colors. Four blues, four grays, one dark green, and one lavender. That's it. No reds. No yellows. No browns. No oranges. I guess Steve Jobs doesn't like those colors.
Update: [2006-08-07] There's a way to trick the Mac into letting you choose a color.
The color scheme is even more restricted. Classic Windows lets you separately color titlebars, controls, windows, tooltips, etc. There are 3, 121,748,550, 315,992,231, 381,597,229, 793,166,305, 748,598,142, 664,971,150, 859,156,959, 625,371,738, 819,765,620, 120,306,103, 063,491,971, 159,826,931, 121,406,622, 895,447,975, 679,288,285, 306,290,176 color combinations. On the Mac, there are two: blue and gray. On Windows though most apps don't really honor a lot of the color settings, so it's not a fair comparison.
My main complaint isn't so much the lack of choice as the usability issue. I use a custom Windows color scheme to highlight the active window. It's really important to me. (I also use a custom Firefox style to highlight the active form control.) I easily lose track of the active window. On the Mac, the active window has a gray titlebar with black text. The inactive window has a gray titlebar with gray text. The difference is subtle. It's hard for me to keep track of the window focus. It's harder to use, in order to make it pretty.
There's a great Mac app called Doodim that provides an incredibly useful feature for people like me: it darkens all but the focused window. This is better than anything I've seen on Windows or Linux. I love this app! Unfortunately it's somewhat slow on my Intel Mac because it's a PowerPC application, and it's running under emulation. I'm also using MenuShade, which darkens the menubar when you're not using it. I tried out some apps similar to Doodim (FocusLayer and Zazen) but they didn't work as well for me. I wish Doodim's functionality was built into the OS.
The Mac approach to limiting choice seems to be largely about the appearance. When it comes to functionality, it's much better. With keyboard shortcuts, the Mac gives me far more choices than Windows or Linux. I'm impressed (but I'd like a little more—there are odd restrictions on which keys I'm allowed to use). Underneath it all, the Unix (BSD) foundation is there and gives me even more power. I'm quite happy to see Python, Ruby, Apache, and so on installed (although I do wonder why they use old versions of Ruby and Apache). I'll take a while to get used to the differences.
Labels: mac
Review: Deck Legend Keyboard #
I've been looking for a new keyboard for about a year now. I'm picky about keyboards. I want them to have a good feel: when the key is sent to the computer, I want to feel something in the key. I was reading reviews on Dans Data and found this:
It's a proper long-travel keyboard with good tactile feedback - not quite as positive as buckling spring, but rather quieter - and impressive durability stats.
That seemed promising. Dan's site also includes this page about “clicky” keyboards, so I know he has good taste in keyboards. That review, along with several others, convinced me to buy the Deck Legend keyboard, even though it wasn't in any stores, and I couldn't try it out first. I also liked the company's attitude. They give you instructions on disassembly, removing keycaps, adding lighting, and so on. And they don't void the warranty for modding. I wasn't planning to do any of these things, but it made me feel better about the company.
Plus, it has cool lighting. Each key is individually lit by an LED. There's also brightness control. And you can install custom keycaps like a skull & bones. It's a “cool” keyboard.
So I ordered it.
Unfortunately the keyboard doesn't feel good to me. It feels very mushy, and there's no feedback when a key has been pressed. At all. In short, this keyboard feels awful. When I press down on a key, it sends a signal to the computer with no "click", and then the key goes "thud" at the bottom.
I returned it.
This makes me quite sad. I really like the company and this keyboard seemed promising. I'm now hunting for another keyboard but haven't found anything really nice. The Logitech Dinovo looks interesting, except the reviews say that it drops keystrokes (it's wireless) and the shift and spacebar keys are hard to press after a few months.
Labels: review
Naming disorders #
Who comes up with names for disorders? Intermittent Explosive Disorder sounds more like a bowel problem than an anger problem. If you think you have it, you can take Simmadoun as treatment. Or you can just take a deep breath and relax.
Environmentally friendly gold mining #
Gold mining involves digging up tons of rock from the ground, using chemicals like cyanide, and then tossing all the rock somewhere. I took a scenic drive along CA-hwy 49 over the weekend, and saw some mining equipment. I also read about a mine that still has gold, but it's too expensive (and probably would raise lots of environmental concerns).
Someday I'd like all gold mines to use gold mining bacteria. They pull the gold out of the ore while leaving the ore in place. Let's dump tons of these bacteria down into the gold mines, let them do their work, and then pull up all the gold. Whee!
Update: [2006-07-14] Researchers have found gold-harvesting bacteria.
Labels: future
Schmap: clever marketing #
The Schmap map/guide folk have done something incredibly clever. They searched Flickr for Creative Commons licensed photos, then emailed the photographers asking for permission to use the photos in their Schmap guides. At first I thought, cool, I'm honored to have my Las Vegas photo in there. The next thing I thought was cool, they're using Creative Commons for business purposes. Today I realized that there's something much bigger than saving money: they're getting free marketing. Lots of bloggers use flickr. These bloggers are posting about being selected for Schmap: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17. It's a mix of people being flattered, confused, and offended.
There's some controversy over whether the ad-supported Schmap application is allowed to use Creative Commons “non-commercial” photos. I do think ad-supported makes it commercial. The Creative Commons non-commercial license lets you use the material for non-commercial purposes without asking permission But by asking permission, I think they can use them despite the non-commercial restriction. They're basically asking for a license to use the photos, and they're not using them under the Creative Commons license. There are also some folk unhappy about Schmap using Creative Commons material but then not licensing their own content under Creative Commons. I don't have a problem with that part. I don't see Creative Commons as being viral. Another issue is whether amateur photography will disrupt the market for professionals. I think it might, but maybe it should. It shouldn't be illegal or immoral for me to give my photos or my programs or my movies or my books or my source code or my music or my services away for free or at any cost I choose.
I think the main reason they asked permission is so that people would blog about Schmap. And it worked. If they had used their own photos, or used Creative Commons commercial licensed photos without asking (which would be legal), nobody would've heard of Schmap.
Feeds are too primitive #
When I find an article or blog post I like, some sites and most blogs allow me to subscribe to a “feed” (implemented with RSS or Atom), so that I can receive more articles and blog posts. The feed is better than an email subscription because I control the subscription. With email, the sender has a list of who subscribe; with feeds, I have a list of what I subscribe to. Leaving this up to the sender means a spammer can subscribe me without permission (and this happens to me all the time). It means someone can put in the wrong email address, and I end up receiving their email (this happened to me recently, and I started receiving email about my being in the 27th week of pregnancy). With feeds these things don't happen, because I control the list.
I think the bigger promise with feeds is the possibility to subscribe in new ways. Right now, I can subscribe to a site's feed. If I see an post I like, I can subscribe to receive other posts from the same site. This assumes that if I like one post from the site, I'll like other posts from that site. Sometimes this is true; sometimes it isn't, especially when the author mixes many topics in the same blog (as I do). If I've marked a set of posts (A) I like, there are many ways to guess what other posts (B) I'll like:
- Posts textually similar, but not identical to, to the ones I marked: words(A) and words(B) overlap, but not completely
- Posts that link to the same articles as the posts I marked: X ∈ (links(A) ∩ links(B)) but X is not commonly linked to
- Posts that are linked to by the same pages as the posts I marked: for many pages X, A ∈ links(X) and B ∈ links(X)
- Posts that share the same tags as the posts I marked: tags(A) and tags(B) overlap
- Posts that are marked by the same people: my set A and your set A overlap, so tell me which posts didn't overlap
There's some remixing going on already with Feedburner, Google Reader, and others, but I want to see more automated creation of feeds based on sets of posts as the input, rather than feeds as the input. To build the kinds of things I'd like requires someone to analyze text, tags, and links for every post. It's a lot of work, which is probably why it hasn't been done.
Why Sun is doomed #
If you have a Sun workstation, an ATI Radeon 7000 with 32 MB of video RAM costs $300.
If you have a PC, ATI Radeon 7000 with 32 MB of video RAM costs around $30.
Why does Sun charge 10 times as much for essentially the same thing? I don't know. If that doesn't convince you that Sun is doomed, read this story.
Decision making #
Gut instinct isn't a good way to make these decisions. There are a lot of counterintuitive things in life. The Decision Education Foundation teaches kids to make better decisions, but it's at a small scale. Analysis and good decision making should be taught in all schools. It's more important than teaching long division or art history or a foreign language. It's probably more important than teaching chemistry or history.
Reducing dependence on foreign oil #
The United States imports more than half the oil it consumes. There are a lot of people here who say we should do X Y Z to “reduce the dependence on foreign oil”. The problem is that X Y Z usually involves reducing demand.
If we reduce demand, prices will go down.
If prices go down, the oil that costs the most to produce will be the first to be dropped. What oil is that? The domestic oil.
So if we reduce demand, a larger portion of our oil will be foreign. We'll shut down domestic oil production, which will increase our dependence on foreign oil. If our oil supply ever gets cut off, we'll be in more trouble than if we had been using more oil, because our infrastructure will have decayed.
To keep prices high, we need to make sure that our reducing demand doesn't lower the price of oil much. The way to do that is to encourage China to consume more oil. That will drive the price up, which will reduce consumption here in the U.S., without leading us to shut down production of oil. Maybe we'll even become an oil exporter. (Ha!)
Labels: future
Firefox cookie management #
There are way too many sites that send me cookies. I don't really want to keep them. However, many sites don't work at all without cookies. I've decided to do three things:
- Allow sites to set cookies, because many sites require cookies.
- Don't allow third-party cookies, because that's mainly used for tracking people across sites.
- Erase most cookies when I close the browser; I allow only cookies from a small set of sites to remain between browser sessions.
I've been using this cookie policy for several years and am happy with it. My Firefox settings are:
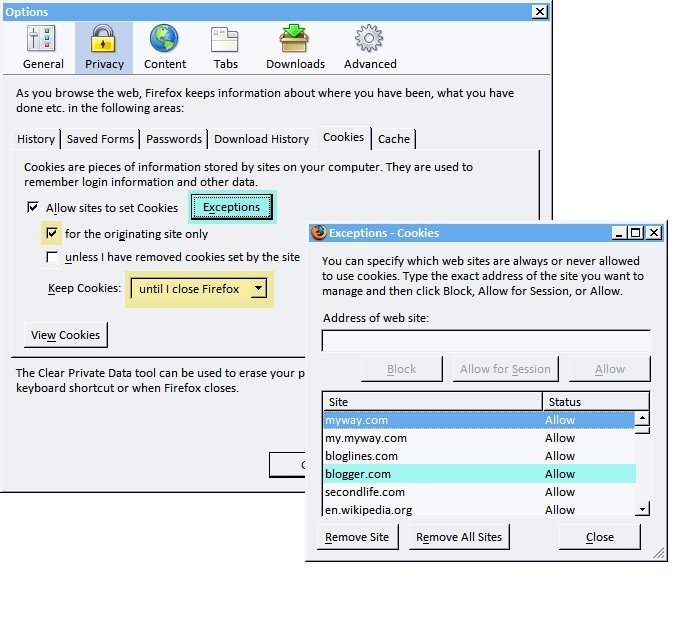
First, I allow cookies for the originating site only, which turns off third-party cookies. I keep cookies until I close Firefox. I also set Exceptions and set each site whose cookies I want to keep to Allow.
Labels: howto
Firefox 1.5 open new windows in tabs #
With Firefox 1.0, I used “single window mode” to force all new windows to instead open in new tabs. With Firefox 1.5, most new windows are redirected to tabs but any window with a custom size will still get its own window. I (and many others) prefer that all new windows be turned into tabs. To do this, go to about:config and set the browser.link.open_newwindow.restriction variable to 0. This was changed as a result of bug 313300; they felt that 2 (resized windows don't become tabs) was a better default.
Labels: howto
The long tail can sting #
If you read the blogs, you'll learn how the long tail is great for business. The long tail can also be a curse. Consider developer communities. If you have a long tail of developers, it's harder to coordinate with all of them. The long tail of developers typically will attach itself to the dominant development platforms (C/C++, Intel x86, DOS/Windows), whereas other platforms (Java, PowerPC, Mac) have small development communities. The dominant platforms cannot coordinate with all the developers, so they must retain backwards compatibility. Their strategy is not to abandon their old systems, but to extend them. C was extended to C++. Intel 8086 was extended to 286 and 386 (remember "real mode" and "protected mode"?) and then later x86 was emulated inside Pentiums. DOS was extended to Windows and then replaced by NT, which still could run DOS programs. In all of these cases, the platforms have become incredibly ugly due to the backwards compatibility. Ask developers if C++ or Java is cleaner, if x86 or PowerPC is cleaner, if Windows or Mac is cleaner, and the answer will be clear: the system that was more recently designed is cleaner and more pleasant to work with. However most developers are still tied to the ugly systems. Why? Because backwards compatibility is the path to success. When you have that long tail of developers, you can't afford to abandon them, so you bend over backwards to keep their old programs working. I can still run Windows programs I worked on in 1993. I can't run Mac programs from 1993 in any nice way. I can still run 8086 programs on a Pentium IV without emulation. I can't run 6800 programs on a PowerPC without emulation. I can compile most C libraries in a C++ compiler. I can't compile C code in a Java compiler. The most popular systems have this curse.
This leaves me pessimistic about ever having clean successful systems. The successful systems are laden with backwards compatibility requirements. Those requirements make the system unclean.
Volume control - an operating system's job #
What should an operating system do? It should manage computer resources. It runs programs, controls access to hard drives and speakers and graphics, allows you to manage files, and so on.
Something I want from the operating system is volume control per application. By default, I want only the focused appliation to play sounds. If another application wants to play sounds, I'd like control over the volume.
The prime use of this, I think, would be to control your web browser's volume while you are surfing the web. I don't like most pages that play music or sounds. I especially don't like it when I have multiple pages up and they want to play their own music. I'd like to play music in a music player while surfing the web, and with only a single volume control, I can't do this.
Operating system makers: please add volume control to every window's titlebar!
Update [2006-01-21]: I just read that Windows Vista will have per-application volume control. Hooray! Unfortunately it won't be in the titlebar. It'll be up to each application to create a widget to integrate volume into their own app, and you can also control volume from a separate window.
Labels: future
Sirius radio security risk #
I contacted Sirius satellite radio customer support, and they emailed back asking me to send them my password in clear text email. They also want the last four digits of my credit card number. Ick.
Sirius seems to have some other bad security practices too.